
Version Control with Git, HTML Basics
These notes are meant for classroom use but also for reading them offline. We will cover the basics of version control with git, as well as the basics of the web stack.
Git
We will be using a version control tool called git to track changes to our code. We’ll also be using GitHub, an online tool for hosting git repositories.
You should already have git installed, if not see the official documentation on how to install git on your operating system.
Why Version Control?
- Keep copies of multiple states of files
By committing you record a state of the file to which you can go back any time. - Create alternative states
Imagine you just want to try out something, but you realize you have to modify multiple files. You’re not sure whether it will works. With version control you can just create a branch where you can experiment or develop new features without changing the main or other branches. - Collaborate in teams
Nobody wants to send code via e-mail or share via Dropbox. If two people work on a file at the same time it’s not clear how to merge the code. Version control lets you keep your code in a shared central location and has dedicated ways to merge and deal with conflicts. - Keep your work safe
Your hard drive breaks. Your computer is stolen. But your code is safe because you store it not only on your computer but also on a remote server. - Share
You developed something awesome and want to share it. But not only do you want to make it available, you’re also happy about contributions from others!
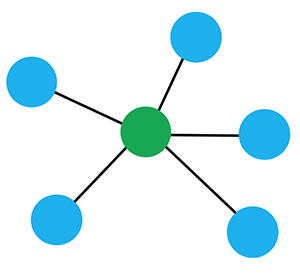
Types of Version Control: Central Repository
- A classical client-server model. One server stores the code and all versions.
- Everybody needs to write to one server.
- All operations (history, commit, branches) require server connection.
- The traditional model: CVS, SVN, etc.
- Pros:
- Simple for small projects.
- Cons:
- Complex for larger projects.
- Who is allowed to write?
- Difficult for community projects.
- How do you apply changes that someone outside your team made?
- Complex for larger projects.
Types of Version Control: Distributed Version Control
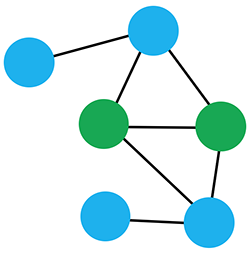
- Everybody has a full history of the repository locally.
- No dedicated server – every node is equal.
- In practice: often a server is used for one “official” copy of the code. This is a server by convention only, there is no technical difference.
- Pros:
- No access issues.
- Make a copy and hack away.
- Ask if partner wants to accept your changes.
- Everything is local.
- Fast!
- No internet connection required.
- Commit often model (once per feature) – don’t sync all the time.
- No access issues.
- Cons:
- More complex principle.
- Extra effort to distinguish between committing and pushing/pulling (synchronizing).
Implementations
- Centralized
- CVS
- SVN
- Team Foundation Server
- …
- Distributed
- git
- Mercurial
- …
- We will be using git in this lecture.
git
- Created by Linus Torvalds in 2005.
- Meaning: British English slang roughly equivalent to “unpleasant person”.
I’m an egotistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘git’. – Linus Torvalds
Why git?
- Popular (~70-80% of searches on google, questions on stack overflow)
- Truly distributed
- Very fast
- Everything is local
- Free
- Safe against corruptions
- GitHub!
Downside: complexity, especially the advanced features…
git model
Whiteboard sketch of git with a server. A git repository is essentially a large graph.
git tutorial
This is a quick intro to git, used in combination with GitHub. This is not a complete tutorial, but will use the most important git features.
In the following, note that the $ symbol signifies a promt of the command line; if you want to copy a command, don’t include the $. This is to distinguish it from output, which has no leading symbol.
We start by configuring git:
1
2
3
$ git config --global user.name "YOUR NAME"
$ git config --global user.email "YOUR EMAIL ADDRESS"
$ git config --global init.defaultBranch "main"
Make sure that this is set to your official school address and your correct name! Also, we name our default branches “main” instead of “master”.
Create a folder for your project
1
2
$ mkdir myProject
$ cd myProject/
Initalize the git repository
1
2
$ git init
Initialized empty Git repository in ../myProject/.git/
What does git do to your file system?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Let's look at what git creates
$ ls .git/
branches config description HEAD hooks info objects refs
# The interesting stuff is in the config file
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
# More interesting for a project with branches and remotes
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = https://github.com/dataviscourse/tutorials
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "gh-pages"]
remote = origin
merge = refs/heads/gh-pages
Now let’s create a file
1
2
3
$ echo 'Hello World' > demo.txt
$ cat demo.txt
Hello World
Let’s add it to version control
1
$ git add demo.txt
Let’s look at what is going on with the repository
1
2
3
4
5
6
7
8
$ git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: demo.txt
That means: git knows that it’s supposed to track this file, but it’s not yet versioned.
Let’s commit the file. Once a file is committed, it’s state is recorded and you can go back to previous versions any time.
1
2
3
4
5
6
7
8
9
10
11
# The -m option specifies the commit message.
# If you don't use it you'll go into an editor to enter your commit message.
$ git commit -m "Committing the test file"
[main (root-commit) dd285ec] Committing the test file
1 file changed, 1 insertion(+)
create mode 100644 demo.txt
# Did it work?
$ git status
On branch main
nothing to commit, working tree clean
That means that now the file is tracked and committed to git. But it’s still only stored on this one computer!
Next, we change a file and commit it again.
1
2
3
4
5
# Now let's change something
$ echo 'Are you still spinning?' >> demo.txt
$ cat demo.txt
Hello World!
Are you still spinning?
Let’s check the status of git!
1
2
3
4
5
6
7
8
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: demo.txt
no changes added to commit (use "git add" and/or "git commit -a")
So git knows that something has changed, but hasn’t recorded it. Let’s commit.
1
2
3
4
$ git commit -m "Added a line to the demo file"
On branch main
Changes not staged for commit:
modified: demo.txt
That didn’t work! You have to add all the files you want to commit every time. There is a shorthand that you can use to add all the tracked files: append ‘-a’.
1
2
3
$ git commit -a -m "Added a line to the demo file"
[main b03178f] added a line to the demo file
1 file changed, 1 insertion(+)
Better. Now, let’s look at what happened up to now
1
2
3
4
5
6
7
8
9
10
11
12
$ git log
commit 372463bab98651ab4b84892a9daf37274f3cc489 (HEAD -> main)
Author: Alexander Lex <alex@sci.utah.edu>
Date: Tue Aug 30 11:30:47 2022 -0600
added the line
commit dd285ec188c4c737d8680e948209331e2d1b5d79
Author: Alexander Lex <alex@sci.utah.edu>
Date: Tue Aug 30 11:28:33 2022 -0600
Committing the test file
Through this cycle of editing, adding and committing, you can develop software in a linear fashion. Now let’s see how we can create alternate versions.
Branching
Now let’s create a branch
1
$ git branch draft
This created a branch with the name draft. Let’s look at all the other branches
1
2
3
$ git branch
draft
* main
We have two branches, draft and main. The * tells us the active branch (the HEAD).
The files in your folders are in the state as they are stored in the active branch. When you change the branch the files are changed, removed or added to the state of the target branch.
Let’s switch the branch.
1
2
$ git checkout draft
Switched to branch 'draft'
Let’s see if there is something different
1
2
3
$ cat demo.txt
Hello World!
Are you still spinning?
No - it’s the same! Now let’s edit.
1
2
3
4
5
$ echo "Spinning round and round" >> demo.txt
$ cat demo.txt
Hello World!
Are you still spinning?
Spinning round and round
And commit
1
2
3
$ git commit -a -m "Confirmed, spinning"
[draft 059daaa] Confirmed, spinning
1 file changed, 1 insertion(+)
We have now written changes to the new branch, draft. The main branch should remain unchanged. Let’s see if that’s true.
1
2
3
4
5
6
$ git checkout main
Switched to branch 'main'
$ cat demo.txt
Hello World!
Are you still spinning?
The text we added isn’t here, as expected! Next we’re going to change something in the main branch and thus cause a conflict.
1
2
3
4
5
6
7
8
9
10
11
# Writing something to the front and to the end in an editor
$ cat demo.txt
I am here!
Hello World!
Are you still spinning?
Indeed!
# committing again
$ git commit -a
[main 2c30b11] Front and back
1 file changed, 2 insertions(+)
At this point we have changed the file in two different branches of the repository. This is great for working on new features without breaking a stable codebase, but it can result in conflicts. Let’s try to merge those two branches.
The git merge command merges the specified branch into the currently active one. main is active, and we want to merge draft into main.
1
2
3
4
$ git merge draft
Auto-merging demo.txt
CONFLICT (content): Merge conflict in demo.txt
Automatic merge failed; fix conflicts and then commit the result.
The result
1
2
3
4
5
6
7
8
9
$ cat demo.txt
I am here!
Hello World!
Are you still spinning?
<<<<<<< HEAD
Indeed!
=======
Spinning round and round
>>>>>>> draft
The first line was merged without problems, The final line, where we have two alternative versions is a conflict. We have to manually resolve the conflict.
Once this is done, we can commit again.
1
2
$ git commit -a -m "resovled conflict"
[main 971f4ab] Merge branch 'draft'
Everything back in order.
1
2
3
$ git status
# On branch main
nothing to commit, working directory clean
Ignoring specifific files and folders
It’s common that you will have temporary and generated files in your working directory that you don’t want to commit to the repository. For example, IDEs will create folders for cached data, or you might generate JavaScript from TypeScript.
To tell git to not add certain files, file types, or folders you can use a .gitignore file in the root directory of your repository.
Here is an example:
1
2
3
4
5
_site/
.sass-cache/
.jekyll-metadata
.idea
*.css.map
These are the basics of git on a local git repository. Now we’ll learn how to sync with other people. This can be done with just git, but we’ll be using GitHub as we’re also using GitHub in the homeworks.
Working with GitHub
First, we’ll create a new repository on github by going to https://github.com/new.
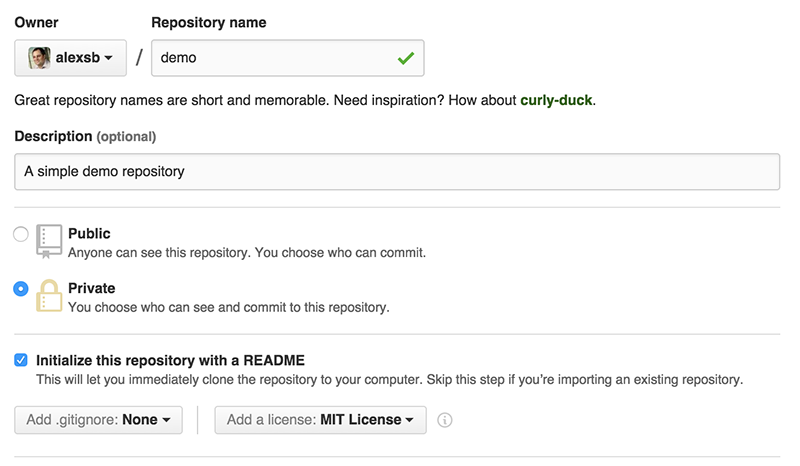
Now let’s clone the repository from GitHub.
1
$ git clone https://github.com/alexsb/Demo.git
Let’s see how the config looks for this one.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = https://github.com/alexsb/demo.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "main"]
remote = origin
merge = refs/heads/main
This creates a local copy of the (empty) GitHub repository. We will just start working with that and commit and push the code to the server. If you’d like to add an existing repository to GitHub, follow these instructions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# What's currently in the repository?
$ ls
LICENSE README.md
# Write something to demo.txt.
$ echo "Hello world!" > demo.txt
# Add demo.txt to the repository.
$ git add demo.txt
# Commit the file to the repository.
$ git commit -a -m "added demo file"
[main 2e1918d] added demo file
1 file changed, 1 insertion(+)
create mode 100644 demo.txt
Now it’s time to push it to the server!
1
2
3
4
5
6
7
8
$ git push
Counting objects: 3, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 324 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/alexsb/demo.git
8e1ecd1..2e1918d main -> main
We have now committed a file locally and pushed it to the server, i.e., our local copy is in sync with the server copy.
Note that the git push command uses the origin defined in the config file. You can also push to other repositories!
Next, we will make changes at another place. We’ll use the GitHub web interface to do that.
Once these changes are done, our local repository is out of sync with the remote repository. To get these changes locally, we have to pull from the repository:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ git pull
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/alexsb/demo
2e1918d..5dd3090 main -> origin/main
Updating 2e1918d..5dd3090
Fast-forward
demo.txt | 1 +
1 file changed, 1 insertion(+)
# Let's see whether the changes are here
$ cat demo.txt
Hello world
Are you still spinning?
Other GitHub Features
- GitHub Issues
Github Issues are a great way to keep track of open tasks and problems. Issues can be references and closed from commits. - GitHub Projects
Projects are similar to trello and allow you to organize a project with issues but also other, simple cards. - Forking & Pull Requests
Forking is essentially making use of the distributed nature of git, while having the benefits of a server. When you fork a repository you make a clone of someone else’s code that you are not allowed to read. The repository appears in your github account and you can start editing the code. If you think you improved the code, you can send a “pull request” to the original owner. The owner can then review your code and merge your modifications into his main repository. Forking is hence virtually the same as branching, with the exception that it resolves issues with write permissions.
GUI Clients
- GitHub Desktop
Good option if you want a GUI client. Download here - Integrated in IDEs
Many operations can be done out of a IDE such as Visual Studio Code or WebStorm
Getting updates to the homeworks
The homeworks are hosted in a git repository on github. Every time we release a homework we will just update the repository. You can then pull from that repository to get the latest homework onto your computer.
To get the homework repository, run the following:
1
2
$ git clone https://github.com/dataviscourse/2022-homework -o homework
$ cd 2022-homework
Note that by using the -o homework option we’re not using the default remote origin but a user-defined remote called homework.
Next, create a new repository on the Github.
Ensure your new repository is private and don’t click the option to “Initialize the repository with a README”.
Run the two commands described on GitHub under the heading “Push an existing repository from the command line”. For my repository these are:
1
2
3
4
# adding your own repository as a remote 'origin'
$ git remote add origin https://github.com/alexsb/dataviscourse-hw.git
# pushing the changes retrieved from the central HW repo to our own repository
$ git push -u origin main
Now your homework repository is all set!
Committing
While working on homework assignments, periodically run the following:
1
2
$ git commit -a -m "Describe your changes"
$ git push
Remember, the git commit operation takes a snapshot of your code at that point in time but doesn’t write to the server.
The git push operation pushes your local commits to the remote repository.
You should do this frequently: as often as you have an incremental, standalone improvement.
Getting new homework assignments
When we release a new assignment we will simply add it to the homework github repository.
To get the latest homework assignments and potential updates or corrections to the assignment, run the following.
1
$ git pull homework main
Make sure to have all your changes committed before you do that.